Fast data websites
Websites designed around the display of data often suffer from poor performance. This post will explore how to avoid this using the primitives of the browser, by changing how we think about data.
A minimalist-styled website only requires plain HTML with a bit of vanilla JS for interactivity. This is not an exhaustive list, but these tips are usually sufficient for writing websites that are perceived as shockingly fast to users:
- Don't allocate objects at runtime after load (preallocate everything).
- Use typed arrays anywhere you need to track more than a handful of things.
- Don't write string-compare heavy code.
- Don't write object-as-map/set for more than a handful of elements.
- Flatten any large group of data into a set of typed arrays.
- Network-fetched data should arrive in typed array compatible binary format - it's easy and a faster format parser is not possible.
Learning how to do this and learning the basics of HTML, CSS, and JS takes a bit of effort, but unlike framework-stack-o-the-week, you don't have to restart every few years, since the standards change slowly, with strong backwards compatibility. Think of the browser runtime as a UI framework, like React or QT, because that's what it ultimately is.
Usually, when something gets "ported to C" or "ported to Rust" and you see a big speedup, it's primarily driven by following these patterns, and has very little to do with the choice of language.
Latency
Why are most of the tips above about avoiding certain operations? The speed at which an operation in a program can be performed is driven by the physical distance data must travel. Norvig and others have compiled helpful lists of latency numbers per operation type, like this one:
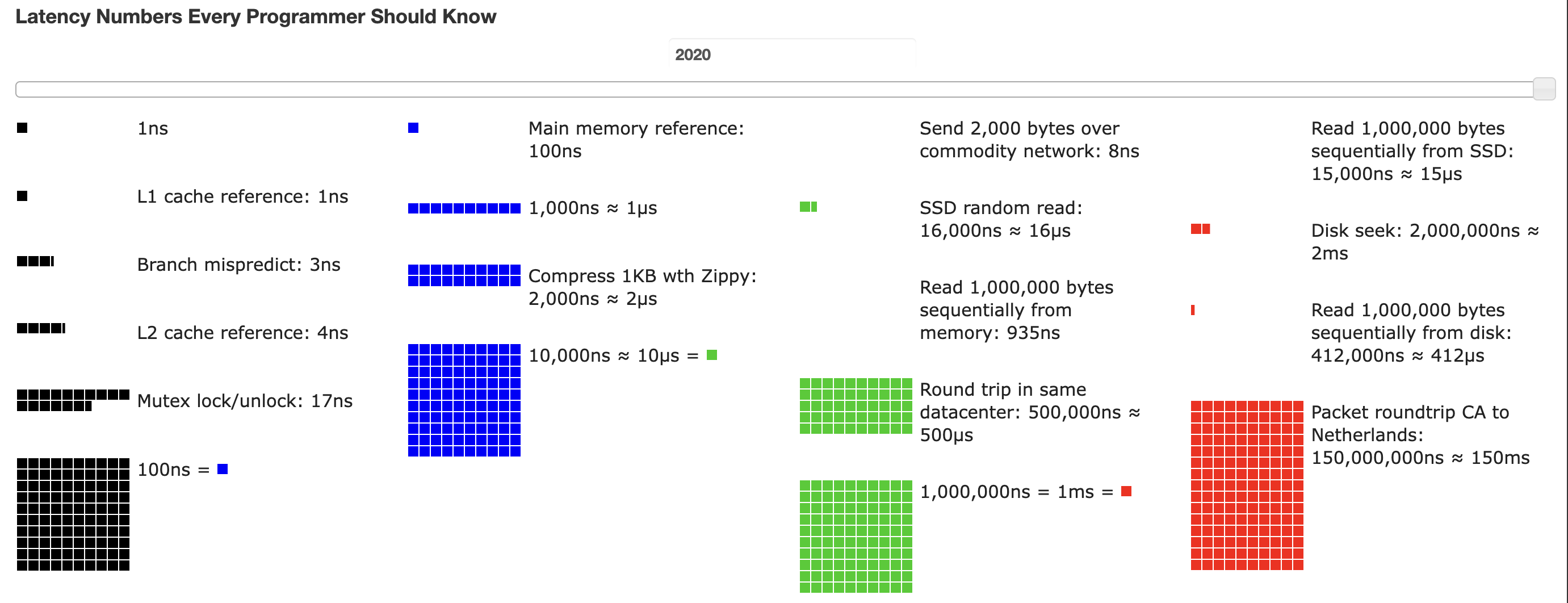 https://colin-scott.github.io/personal_website/research/interactive_latency.html
https://colin-scott.github.io/personal_website/research/interactive_latency.html
These are physical constraints, and no magic programming language design can overcome physics. Porting to WASM or vulkan or ____ won't save you, and it isn't necessary where fast primitives exist in JS.
Exceptions exist, such as When native intrinsic libraries like AVX are required to go beyond the performance afforded by a naive data-oriented C implementation for an additional ~5-10x speedup. In these situations, first consider sharding or aggregating your data. If that won't do, ditch the web and use a lib like SDL3 to build a crossplatform native app.
Don't skip ahead in this optimization order - each additional layer comes at cost to accessibility (the single most important quality of a data visualization), so consider the simpler approach carefully before moving on, but don't be afraid to either. Writing a raylib GUI in C is not that more difficult or different than writing a vanilla style data web page.
Setting a baseline
War and Peace, Project Guttenberg loads instantly and uses no amount of perceivable CPU on a modern device. I can cmd+f search for strings, and results return instantly. Given this, be confident that your website can comfortably display as much text as a half million+ word novel. Well before this, data visualizations should utilize aggregation for simple practicality reasons.
Similar examples can be thought of and measured for other types of data. For example, try running a high res video on a simple HTML page to get a feel for runtime cost of a page that rapidly updates every pixel on the screen.
Understand that if you're not meeting the baseline comp you've set, there is something you have written or (more likely) a dependency that you've taken that has blown the budget unneccessarily. Simplify and delete until you are back to baseline.
Awareness of runtime
When code becomes thousands of times slower than the naive implementation, it is rarely the case that a coder sat down and tried to write something fast, and the slow page was the result. Always set a baseline for the type of page being written, and periodically compare changes against this baseline. As of 2025, the performance profiling tools that come with firefox and chrome are both capable of measuring a page's performance and describing where the runtime is being spent.
This process is important when considering dependencies. Simply do not add dependencies that move the needle in a bad direction significantly. Do not add dependencies that take over the runtime. Do not add dependencies that obscure the runtime. Stay as close to a while(true) {...} update loop as you can manage. Do this, and adding small functional dependencies is not a big deal - take advantage of the npm ecosystem, and appreciate the small-module-UNIXy philosophy that drove much of early node/JS development. While small libs like leftpad are often bemoaned, small functional libs are easy to replace with a more minimal or optimized implementation in the future, while frameworks only get harder to do the same over time.
Screen refresh rate
Humans perceive animation when objects move at about 10 fps. It's tempting to settle here and call it a day. Instead, set a goal at the beginning of authoring a page to maintain the max screen refresh rate of a blank page. This will likely be something like 30 fps, 60 fps, or 140 fps depending on the hardware you have available to test on. Set a hard rule that you won't ever ship a change that deviates from your objective by 10%. I aim for 140 fps whenever possible, which gives 7-8 ms per frame to play with. If I really need to perform an operation that cannot fit in this budget comfortably, I move it to a worker thread to avoid UI jitter. I never add more than a couple web workers, even when I know most systems could handle it. The point is not to speed things up, but to simply move blocking work off the UI thread. Use the same judgement for these tasks that you would for a networked fetch call, because latency will be in a similar ballpark (10-1000 ms).
If you take away nothing else from this, take away that you should always maintain a minimum of 60 fps when writing a web page. Don't do things that make you unsure if you can or have achieved this.
7-22-25